
Why is this question interesting in the case of a language which hardly has any non-sonorant codas and in which voicing contrast is limited to stops? This article aims to be a tiny step in the research of pre-sonorant voicing, which — as discussed in §1 — is constrained to languages with final delaryngealization. We will answer the question raised above by the help of an acoustic analysis examining 6 native speakers’ laboratory speech the realizations of utterance-final /b/, /d/ and /g/ presented in §3 after giving a short introduction to the syllable structure of Spanish in §2.
Pre-sonorant voicing, i.e., when a voiceless/devoiced obstruent assimilates in voicing to a following sonorant, has raised recurrent interest among phonologist mostly due to the apparent activity of a non-contrastively specified segment acting as a trigger in voicing assimilation. In most languages pre-sonorant voicing targets word-final (or syllable final) obstruents. In some languages vowels pattern with sonorants in that they also trigger voicing assimilation, while in others vowels do not trigger voicing, or contrarily, it is mostly vowels that voice the preceding obstruent and not sonorant consonants. The process often targets only subclasses of obstruents. In some accounts sonorant voicing seems to be a gradient phonetic process, while in others it shows up as categorical.
Pre-sonorant voicing is generally restricted to word-final position. An example is Slovak as reported in Pauliny (1979) and Rubach (1994). In Slovak a word-final obstruent is realized as voiced if it is followed by a voiced obstruent, (1a), a sonorant consonant, (1b), or a vowel, (1c), in the next word, the process applies to clusters as well, (1d), but is not operative within the word, (1e).
The same positional restriction holds for Ecuadorian Spanish as well (Robinson 1979 and Lipski 1989), or Dutch (De Schutter & Taeldeman 1986 cited by Strycharczuk & Simon, to appear). In the Ecuadorian variety of Spanish /s/ undergoes voicing if it is followed by a vowel in the next word, (2a), however, pre-vocalic voicing does not apply within the word, (2b). Note that there is re-syllabification in Spanish across the word boundary. In Dutch word-final fricatives can be voiced before vowel-initial words, (3a) and in compounds, (3b), but not within the word, (3c).
As for the trigger of pre-sonorant voicing more variation is observed among languages. In some languages — like Slovak, shown in (1), Kraków Polish (Rubach 1996) or West-Flemish (Strycharczuk & Simon, to appear) — sonorant consonants and vowels pattern together and induce voicing assimilation. West-Flemish differs from the other Southern Dutch dialects in that in those dialects, as reported in De Schutter & Taeldeman (1986) and shown in (3), only vowels voice the final fricative of the preceding word, while in West-Flemish fricatives are voiced before sonorant consonants as well across word-boundaries: zes jaar [zɛz jaːr] ‘six years’. Similarly to the Southern Dutch dialects, /s/-voicing in Ecuadorian Spanish is also induced only by vowels, (2). Standard Peninsular Spanish is exactly the other way round (Hualde 2005): /s/ is voiced if followed by a voiced obstruent or a sonorant consonant, (4a), but is not voiced in pre-vocalic position, (4b), the process is not limited to word-final position, syllable-final /s/ also undergoes voicing.
It has been reported in a number of cases that sonorant-voicing targets only subclasses of obstruents. In Dutch only fricatives undergo voicing assimilation, in Spanish only /s/, as shown above. Simon (2010) found pre-sonorant voicing in fricatives, but not in stops in the production of West-Flemish speakers. An illustrative example is provided by Jiménez & Lloret (2008) who report a dialect continuum in Catalan: in Central Valencian there is no voicing of word-final consonants before vowels, Alguerés and Valencian dialect B have sibilant voicing, in Valencian dialect A apart from word-final sibilants, alveolar affricates also become voiced in pre-vocalic position, Central Catalan has variable /f/ voicing as well, while in Alicantino all word-final obstruents undergo voicing when followed by a vowel. Note that all the languages to our knowledge that have pre-sonorant voicing also have word-final devoicing, more precisely, these languages are traditionally considered to have voicing neutralization in final position. In this paper we will not tackle the question why this should be so, neither will we dwell upon the issue of complete vs. partial neutralization in this context. We will only try to find out whether the claim that “those languages that have pre-sonorant voicing also have word-final devoicing” holds for Spanish or not. Although the question is very simple it is not so straightforward to find the answer due to the phonotactic restrictions holding in Spanish.
According to Quilis (1993) 68.8% of Spanish syllables are open, the vast majority of codas consist of a sonorant consonant or /s/ (or rarely both in this order, e.g., transcripción ‘transcription’). In the present work we will not consider the well-known coda aspiration which to a varying extent characterizes basically all Spanish varieties, neither will we talk about the so called spirantization of voiced stops, we will rather focus on obstruents in coda position. Stops in post-nuclear position rarely contrast (never in voicing) and occur in words that are not very frequent, e.g., acto ‘act’ vs. apto ‘apt’, absorción ‘absorption’ vs. adsorción ‘adsorption’. Their actual realizations cover a wide range, the sequence /kt/, for instance, can appear as [kt], [gt], [ɣt], [θt], [xt], [ht], [st] or even vocalized (Quilis 1993). Fricatives, apart from /s/, do not occur in word-internal coda position.☞/g/ in words like signo ‘sign’, pragmática ‘pragmatics’ is realized as [χ] in northern Spanish. As for word-final position, the only stop that occurs in the native vocabulary is /d/. Its realization depends on the regional dialect and style, it can be deleted, especially in polysyllabic words; generally it is described as [ð] or [θ], while in Catalan speaking territories as [t]. All the other stops only occur in recent borrowings, which means that it is quite forced to speak about contrast (or neutralization) in this position. According to Hualde (2005: 148–149) /p/ and /t/ are either realized as such, or are deleted. /b/ has a word-specific pronunciation, e.g., pub is realized as /paf/ by most speakers, while club contains a final [b], [β], [p] or is deleted. As for the velars, both /k/ and /g/ can be realized as [k], [g] and [ɣ], while word-final /g/ can also appear as [x]. Hualde also says that “word-internal coda plosives were probably on their way out of the language. Before the Spanish Academy was established we often find forms like dino for digno ‘worthy’ […] The Academy, however, decided to keep many of these etymological consonants in the orthography” (2005: 147). Nowdays most educated people generally pronounce these consonants, although there are many exceptions. This explains the substantial variation in the pronunciation mentioned above, and the fact that in lower sociolects and regional dialects the loss of these coda consonants becomes more frequent.
| labial | dental/alveolar | alveo-palatal | palatal | velar | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| voiced | vless | voiced | vless | voiced | vless | voiced | vless | voiced | vless | |
| stops | b | p | d | t | g | k | ||||
| fricatives | f | s/θ | x | |||||||
| affricate | ʧ | |||||||||
Turning to fricatives, apart from /ʝ/ Spanish has no voiced fricatives (see table 1 for Spanish obstruents). This corresponds to universal tendencies, since to maintain friction and phonation at the same time contradictory articulatory targets are necessary (Ohala 1983), which causes an uneasy balance. In order to produce turbulent noise a high velocity of airflow is needed, which can be obtained by open glottis and a narrow constriction in the oral cavity. This also means that the air pressure below the glottis is smaller or equals that within the oral cavity. On the other hand, in order to produce voicing, vocal folds should be loosely compressed so the air pressure builds up below the glottis. If supraglottal pressure exceeds subglottal pressure, vocal fold vibration stops and voicing disappears. This explains why we find languages that have voiceless fricatives but no voiced fricatives (e.g., Korean) and not the other way round. Spanish is almost like that, note that /ʝ/ in coda position is realized as the glide element of a closing diphthong: rey [rei̯] ‘king’. Let us now look at how our speakers pronounce word-final voiced stops.
The word-final voiced stops analyzed in this paper form part of a larger experiment on voicing assimilation, especially sonorant voicing in Spanish. A laboratory speech production experiment was carried out to study the voicing properties of utterance-final /b/, /d/ and /g/ in Northern
The test words were pub, virtud ‘virtue, power’ and blog in utterance-final position, all stressed before the segment under scrutiny. Stimuli were embedded in carrier sentences. The test also contained final /t/ and /p/ for the sake of comparison.
Subjects read the test sentences and fillers from screen in randomized order, which was generated by SpeechRecorder (Draxler & Jänsch 2012). Each test sentence was read 5 times, but the first reading was considered as the familiarization phase and was not taken into consideration. This means one occurrence by 6 speakers by 4 readings, which gives 24 realizations for each segment. Recordings were made in a sound-attenuated room by a Sony ECM-MS907 microphone to a laptop through an M-Audio MobilePre USB preamplifier external sound card, the recordings were sampled at 44100Hz. The spectrograms were segmented manually by the author and voicing measurements were carried out in Praat (version 5.3.12; Boersma & Weenik 2005) with default settings (pitch range: 75 Hz–500 Hz, maximum period factor: 1.3, maximum amplitude factor: 1.6, pitch setting was optimized for voice analysis) and checked manually.
The overall results of the experiment are displayed in figure 1. All the stops under scrutiny are realized voiceless in utterance-final position (on average, with 90% or more of unvoiced frames), although, the actual realizations, as expected, are quite varied.
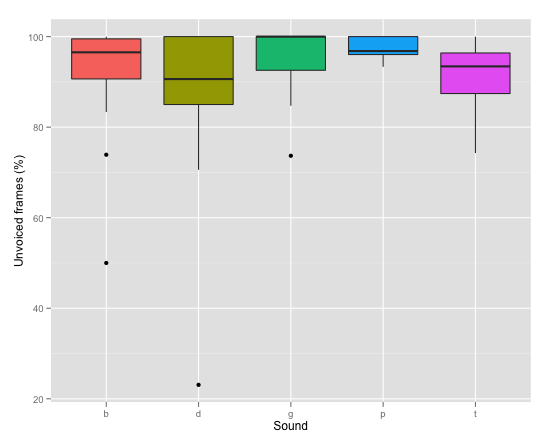
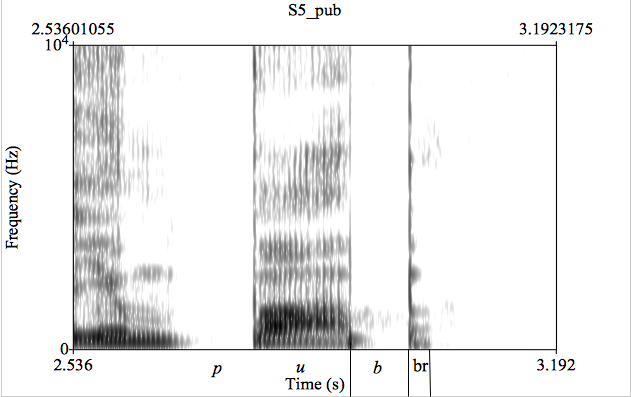
The word pub according to Hualde (2005) is realized by Spaniards as [paf]. This is borne out as a consistent strategy only for two out of our six speakers, they realized all instances of final /b/ as [f]. Three speakers preferred [p], but two of them often pronounced it with no release or in a few cases as a voiceless bilabial fricative. There was only one speaker who pronounced both pub and ketchup with a final [p]. His p’s in the first word were consistently somewhat more voiced than in the second word (87.61% of unvoiced frames opposed to 97.13% of unvoiced frames), voicing entering from the preceding vowel and dying out during the closure phase. In one case (figure 2) with a fair amount of phonation during closure and a schwa-like burst, this was one of the most voiced realizations of the final segment in pub with 73.91% of unvoiced frames for the whole segment (closure+burst). If this item is removed from the calculations, the average of unvoiced frames for the final stop in pub for speaker 5 rises to 91.5%. The sixth speaker deleted the final consonant in half of the cases and once pronounced a half-voiced labiodental stop (50% of unvoiced frames) indicated as a black dot on the boxplot in figure 1.
Final /p/ in the word ketchup was generally realized as such. Two speakers, however, consistently in all the test words pronounced [kepʧu], that is to say, deleted the final stop that violates the phonotactics of Spanish, but still preserved the segment in a different position. Speaker 4 pronounced [kepʧu] in 50% of the cases and [kepʧup] in the other half.
Utterance-final /t/ is realized as [t] by all the speakers in all the cases. Only speaker 5 realized /d/ as well consistently as [t], the same speaker who pronounced both pub and ketchup with [p], again with a slight difference in their phonetic voicing: /d/ contained 91.75% of unvoiced frames, while this value is 94.68% for /t/. This data is not enough to draw any conclusions about voicing contrast in this position, firstly, because more data are needed to carry out statistical analyses, but it is hard to obtain such data since final /d/ is seldom realized as [t] by speakers of Northern Peninsular Spanish. Secondly, because it is difficult to imagine that speakers of Spanish are sensitive to 3–6% of voicing in the case of almost completely devoiced segments. Obviously, only perceptual experiments could clarify this doubt. Speaker 6 also pronounced a dental stop in this case, but in one case it was an articulatory gesture perceptible only from the vowel transition rather than a proper consonant, therefore, impossible to carry out acoustic measurements on it. In two cases he produced a very short closure (44 ms and 25 ms, respectively) followed by a schwa-like release, both of these segments are significantly more voiced than /d/ in final position generally is (23% of unvoiced frames and 70.58% of unvoiced frames, respectively) showing up as black dots on the boxplot in figure 1. Speaker 1 deleted the final consonant of virtud in half of the cases, all the other instances for all our speakers are realized as [θ] as illustrated in figure 3.

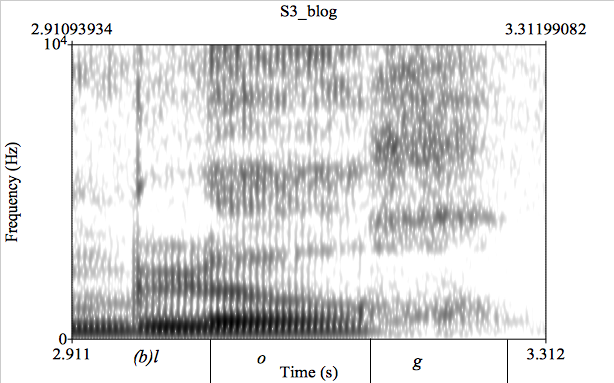
The individual strategies for the “violating” final stops appear in the realizations of the test word blog as well. Most instances of utterance-final /g/ were realized as a voiceless velar or uvular fricative (figure 4), which is not surprising, since this fricative appears in final position in a handful of mostly marginal patrimonial words (e.g., boj ‘shoe-tree’) only one of which is frequent and known by all Spanish speakers (reloj ‘watch’). Speaker 1 deleted the final segment of blog in half of the cases, note that this speaker applied the same strategy for final /d/ as well. Speaker 5 again consistently pronounced a stop in this position (as for pub and virtud), in this case [k] sometimes with a schwa-like release and in the speech of speaker 6 we observe the same vacillation as mentioned earlier: he too preferred [k], but also produced [x]/[h] as the final consonant of blog.
We can claim that in accordance with other languages with pre-sonorant voicing, Spanish also shows word-final devoicing. The actual realization of stop-final words is speaker and word-dependent. Speakers mostly realize these segments as voiceless fricatives, in our data one speaker consistently and another one to some extent pronounced them as voiceless stops. Independently of the manner of articulation, the final consonant is almost without exceptions realized with no phonation.
Boersma, Paul and David Weenik. 2005. Praat: Doing phonetics by computer (version 4.3.19). Retrieved on 20 June 2005 from www.praat.org.
De Schutter, Georges and Johan Taeldeman. 1986. Assimilatie van Stem in de Zuidelijke Nederlandse Dialekten. In: Magda Devos and Johan Taeldeman (eds.), Vruchten van z’n akker: opstellen van (oud-) medewerkers en oud-studenten voor Prof. V. F. Vanacker. Ghent: Seminaire voor Nederlands Taalkunde. 91–133.
Draxler, Christoph and Klaus Jänsch. 2012. SpeechRecorder — a universal platform independent multi-channel audio recording software (version 2.2.1). Retrieved on 30 March 2012 from www.phonetik.uni-muenchen.de/Bas/software/speechrecorder/.
Hualde, José Ignacio. 2005. The Sounds of Spanish. Cambridge: Cambridge University Press.
Jiménez, Jesús and Maria-Rosa Lloret. 2008. Asimetrías perceptivas y similitud articulatiora en la asimilación de sonoridad del catalán. Cuadernos de Lingüística del I.U.I. Ortega y Gasset 15: 71–90.
Lipski, John. 1989. /s/ voicing in Ecuadoran Spanish: Patterns and Principles of Consonantal Modification. Lingua 79: 49–71.
Ohala, John J. 1983. The origin of sound patterns in the vocal tract constraints. In: Peter F. MacNeilage (ed.), The production of speech. New York: Springer-Verlag. 189–216.
Pauliny, Eugén. 1979. Fonológia slovenského jazyka. Bratislava: Slovenské pedagogické nakladateľstvo.
Quilis, Antonio. 1993. Tratado de fonética y fonología españolas. Madrid: Gredos.
Robinson, Kimball L. 1979. On the voicing of intervocalic s in the Ecuadorian highlands. Romance Philology 33: 132–143.
Rubach, Jerzy. 1994. The lexical phonology of Slovak. Oxford: Oxford University Press.
Rubach, Jerzy. 1996. Nonsyllabic analysis of voice assimilation in Polish. Linguistic Inquiry 27: 69–110.
Simon, Ellen. 2010. Phonological transfer of voicing and devoicing rules. Evidence from L1 Dutch and L2 English conversational speech. Language Sciences 32: 63–86.
Strycharczuk, Patrycja and Ellen Simon. to appear. Obstruents before sonorants. The case of West-Flemish. Natural Language and Linguistic Theory.